本文最终实现一个简单的 LinearLayoutManager(只支持 VERTICAL)方向,适合对 LayoutManager 整体流程的学习与理解,整体代码分为多个文件,每个文件都是对前一段代码的补充,方便理解,整体项目源码已提交 Github: LayoutManagerGradually,代码里面写了很多很多注释,如果不想浪费时间,可以直接看代码运行,跳过这篇文章,把每一个 LayoutManager 都跑一下体验结合代码看看。
自定义 LayoutManager 的必要元素
继承
RecyclerView.LayoutManager并实现generateDefaultLayoutParams()方法重写
onLayoutChildren第一次数据填充的时候数据添加重写
canScrollHorizontally()和canScrollVertically()方法设定支持滑动的方向重写
scrollHorizontallyBy()和scrollVerticallyBy()方法,在滑动的时候对屏幕以外的 View 进行回收,以及填充即将滑动进入屏幕范围内的 View 进行填充重写
scrollToPosition()和smoothScrollToPosition()方法支持
其中onLayoutChildren 和 scrollHorizontallyBy/scrollVerticallyBy 是最核心且最复杂的方法,这里稍微拎出来讲一下
onLayoutChildren
这个方法类似于自定义 ViewGroup 的 onLayout() 方法,RecyclerView 的 LayoutManager.onLayoutChildren 在以下几个时机会被触发:
- 当
RecyclerView首次附加到窗口时 - 当
Adapter的数据集发生变化 - 当
RecyclerView被 执行RequetLayout的时候 - 当
LayoutManager发生变化时
scrollHorizontallyBy/scrollVerticallyBy
方法的主要作用包括:
更新 ItemView 的位置:根据传入的垂直滚动距离(dy 参数),更新子视图在屏幕上的位置。通常调用
offsetChildrenVertical方法。回收不可见的 ItemView:在滚动过程中,一些 ItemView 可能会离开屏幕,变得不可见。
scrollVerticallyBy方法需要负责回收这些子视图并将它们放入回收池,以便稍后复用。添加新的 ItemView:在滚动过程中,新的 ItemView 可能需要显示在屏幕上。
scrollVerticallyBy方法需要从回收池中获取可复用的视图并将它们添加到屏幕上。这通常涉及到调用RecyclerView.Recycler的getViewForPosition方法。返回实际滚动距离:由于 ItemView 的数量有限,滚动可能会受到限制。例如,当滚动到列表顶部或底部时,滚动可能会停止。在这种情况下,实际滚动的距离可能会小于传入的
dy参数。scrollVerticallyBy方法需要返回实际滚动的距离,以便RecyclerView可以正确地更新滚动条和触发滚动事件。
概念就简单讲这么多, talk is cheap show me the code,直接看代码理解会比较深刻
逐步实现
要实现一个可用的 LayoutManger 通常我们需要实现以下流程
- 数据填充并且只需要填充屏幕范围内的 ItemView
- 回收掉屏幕以外的 ItemView
- 屏幕外 ItemView 再回到屏幕后,需要重新填充
- 对滑动边界边界进行处理
- 对 scrollToPosition 和 smoothScrollToPosition进行支持
我们不用一上来就实现最终的效果,而是一步一步来,看看 LayoutManger 是怎么渐渐地变化,最终能跑起来的。
0 最简单的 LayoutManager
代码查看:MostSimpleLayoutManager,我们关注 onLayoutChildren 方法:
1 | override fun onLayoutChildren(recycler: RecyclerView.Recycler, state: RecyclerView.State?) { |
上面的代码主要演示了,如何利用addView layoutDecorated等方法,将 ItemView 添加到 RecyclerView 上。代码可见是 将所有的 ItemView(即使它在屏幕上不可见)一次性全部加载到了 RecyclerView上, 这里一般不这么做,只是这里这里只是最简单地演示一下整体是如何工作的。
运行在手机上能看到这样的效果:Item数据已经被全部添加到界面上了,并且各个方向的滑动都支持。

1 更合理的数据添加方式
对最开始的代码进行优化,只在屏幕范围内的区域进行数据的添加,这样就不需要一次性将所有数据就添加上去,如果 Adapter 的 ItemCount 足够巨大,for all addView 的话,很容易就 OOM。
1 | override fun onLayoutChildren(recycler: RecyclerView.Recycler, state: RecyclerView.State) { |
2 对屏幕外的View回收
代码查看:LinearLayoutManager2
RecylerView 没有 recycler 怎么行呢?当 RecylerView 的 ItemView 滑出屏幕后我们需要对齐进行回收,实现的话需要在 scrollVerticallyBy中,比较复杂的逻辑就是怎么去判断:ItemView 在屏幕以外,最后利用:removeAndRecycleView方法进行回收
1 | override fun scrollVerticallyBy(dy: Int, recycler: RecyclerView.Recycler, state: RecyclerView.State?): Int { |
运行在手机上能看到这样的效果:滑出屏幕外的ItemView 被回收掉了

3 向上滑动的时View的填充
代码查看:LinearLayoutManager3
1 | override fun scrollVerticallyBy(dy: Int, recycler: RecyclerView.Recycler, state: RecyclerView.State?): Int { |
运行在手机上能看到这样的效果:向上滑动的时候,底部陆续有元素填充,但向下滑动的时候没有填充数据

4 两个方向的View填充
代码查看:LinearLayoutManager4
补齐从上往下滑之后添加的逻辑
1 | private fun fillView(dy: Int, recycler: RecyclerView.Recycler) { |
运行在手机上能看到这样的效果:向上或者滑动的时候,底部陆续都有元素填充

5 对顶部和底部滑动边界处理
代码查看:LinearLayoutManager5
对于前面的实现会发现会:不停地下滑或者上滑会留出来巨大的空白。这里对填充 View 的逻辑进行改造,需要进行边界检测。
1 | override fun scrollVerticallyBy(dy: Int, recycler: RecyclerView.Recycler, state: RecyclerView.State?): Int { |
这里的整体注释我写在了代码里面,可以看图稍微理解一下,以向上滑动为例:假设这一次滑动的距离非常非常大(想象成10000像素),如果直接滑动的话,我们有50个元素,每个元素高度100像素,最大高度也只有50x100=5000,那么滑动后一定会留下大量空区域。需要对当前传入的这 10000 像素做调整:只给到可滑动的最大距离,如果不能滑动了就返回0。
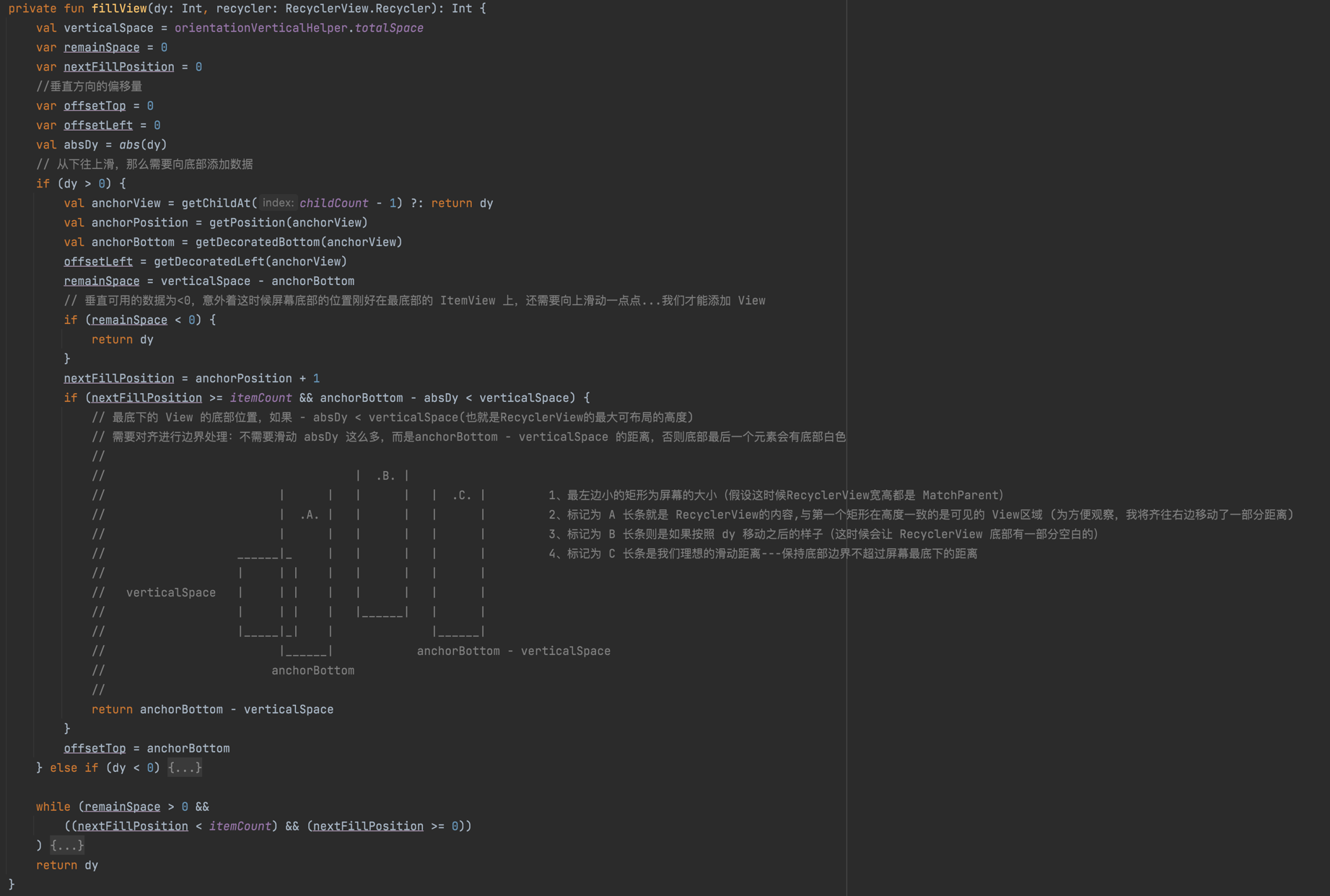
运行在手机上能看到这样的效果:向上或者滑动的时候,达到最大的位置时候是不能再滑动的。

6 实现 scrollToPosition
代码查看:LinearLayoutManager6
到这里这个 LinearLayoutManager 看着已经能正常运行了,但一般还需要支持scrollToPosition 和 smoothScrollToPositio
1 | private var mPendingScrollPosition = RecyclerView.NO_POSITION |
scrollToPosition 的实现比较简单,如上代码所示:在 scrollToPosition 的时候记录一次目标position,再 requestLayout 一波,还记得之前有提到过:onLayoutChildren 会在 requestLayout 的时候调用一次,于是再将onLayoutChildren逻辑改写,不再从第0个元素开始,而是从目标位置进行布局。
运行在手机上能看到这样的效果:点击 scrollTo30 将会滑动到 第30个位置。

7 实现 smoothScrollToPosition
代码查看:LinearLayoutManager7
要实现自定义的 smoothScrollToPosition 动画效果,这一块如果要完全自己实现的话比较复杂,可以直接使用系统提供的 LinearSmoothScroller改造,也可以继承 RecyclerView.SmoothScroller 自定义,也可以完全不使用 SmoothScroller, 照着 SmoothScroller 的实现使用类似 ValueAnimator 自定义动画,添加动画 UpdateListener,在 onAnimationUpdate 的时候动态计算布局从而实现滑动动画,这里拿 LinearSmoothScroller 举例:
1 | override fun smoothScrollToPosition( |
运行在手机上能看到这样的效果:点击 smoothScrollTo30 将会有个动画效果滑动到第30个位置。

以上基本上一个自定义 LayoutManager 的雏形就已经完成了,虽然只实现了一个方向的滑动,但是其原理都是一样的,剩下的就是各种细节的打磨了,可以加各种自己想要的效果,比如:指定位置 放大一定的系数,或者更炫酷的滑动动画…
总结
本文主要整理了自定义 LayoutManager 的必要元素,以及其核心方法 scrollHorizontallyBy/scrollVerticallyBy、onLayoutChildren 的作用与调用时机,接下对实现一个简单的 LinearLayoutManger 进行逻辑拆解,从最简单的不滑动回收和填充以及不含滑动边界检测,到最终一个具备基本功能的 LayoutManger
源码:https://github.com/VomPom/LayoutManagerGradually
参考:
]]>





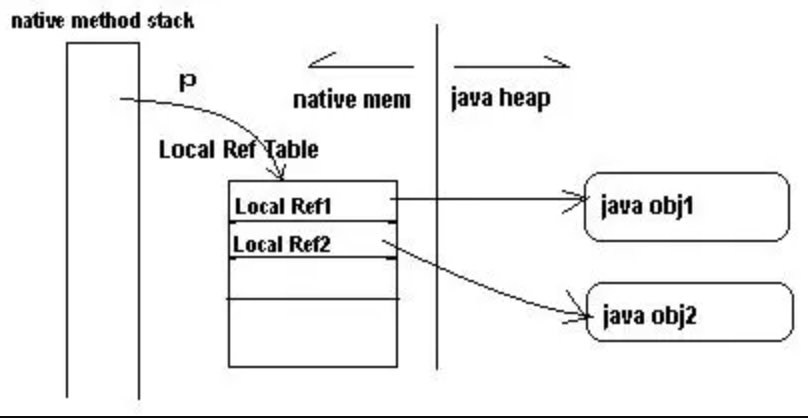
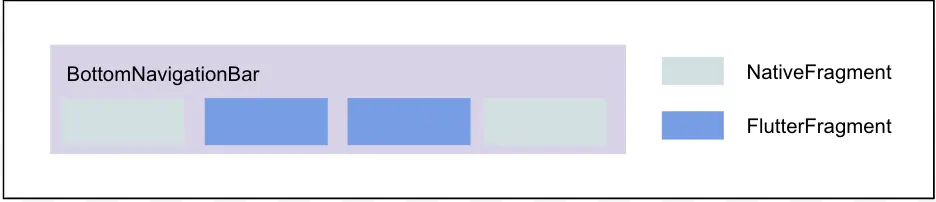
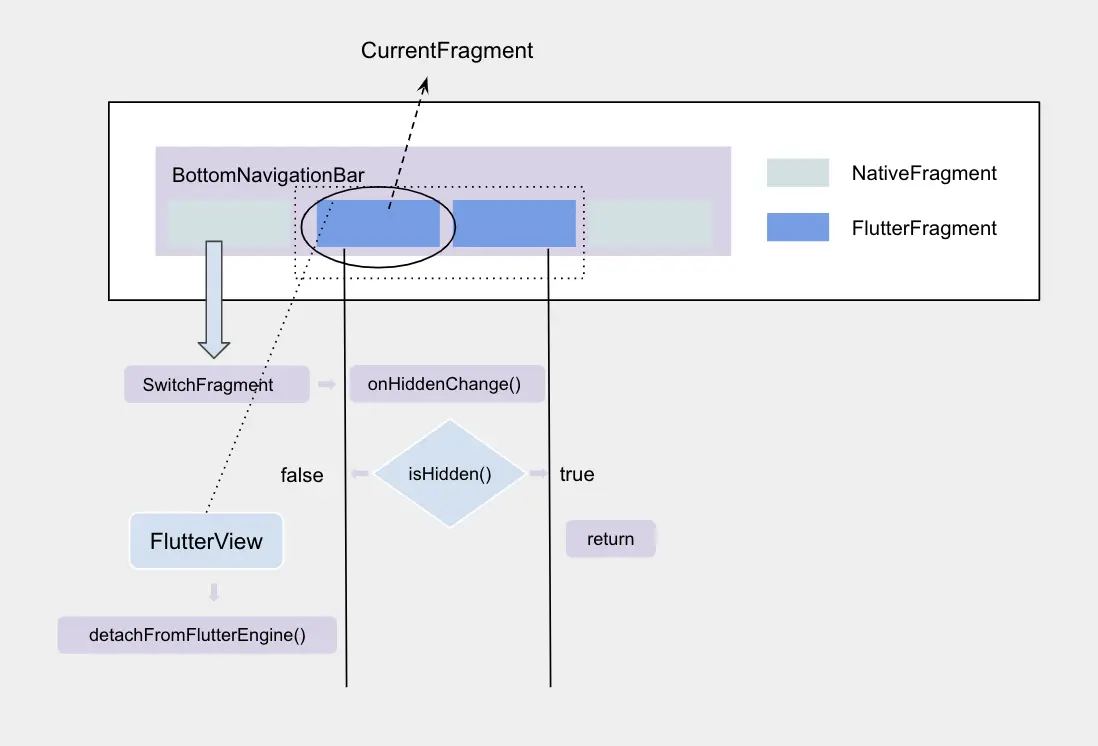
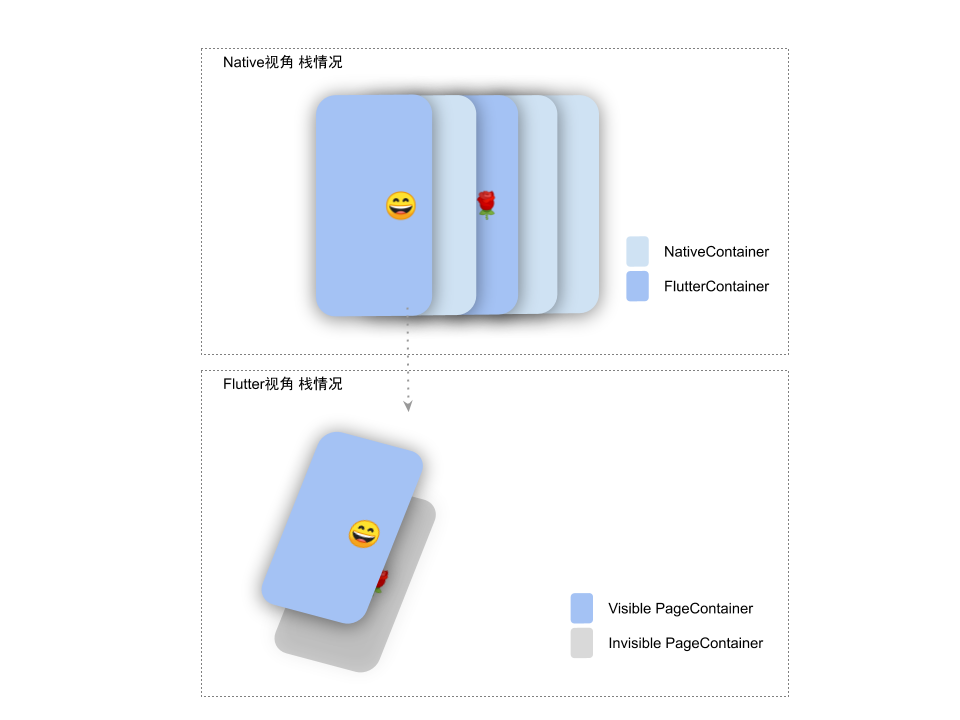
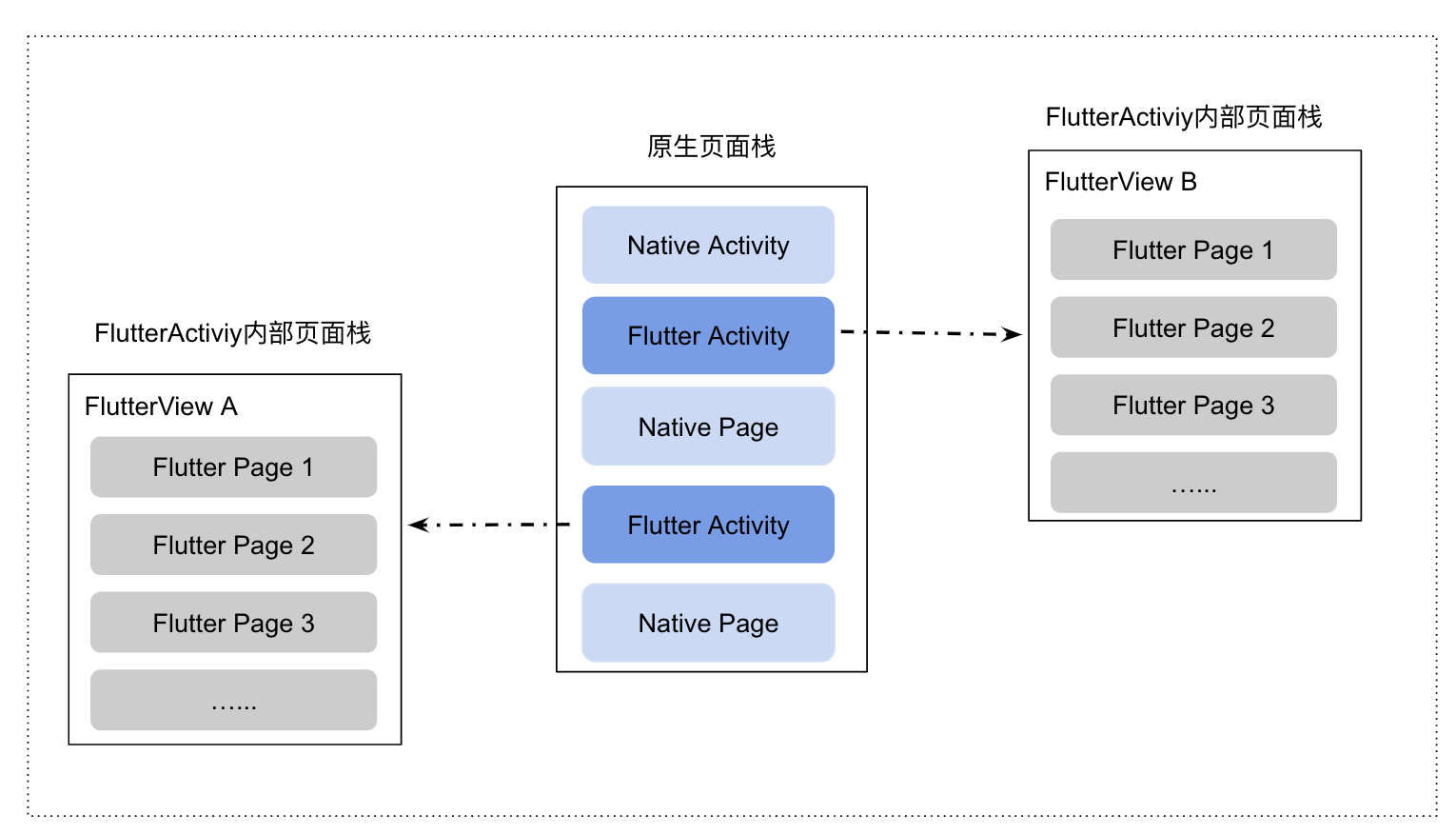 对于 FlutteActivity 或者 FlutterFragment 中的 Flutter 页面来说我们需要将其与原生页面对齐,页面栈变成下图会更容理解:
对于 FlutteActivity 或者 FlutterFragment 中的 Flutter 页面来说我们需要将其与原生页面对齐,页面栈变成下图会更容理解:
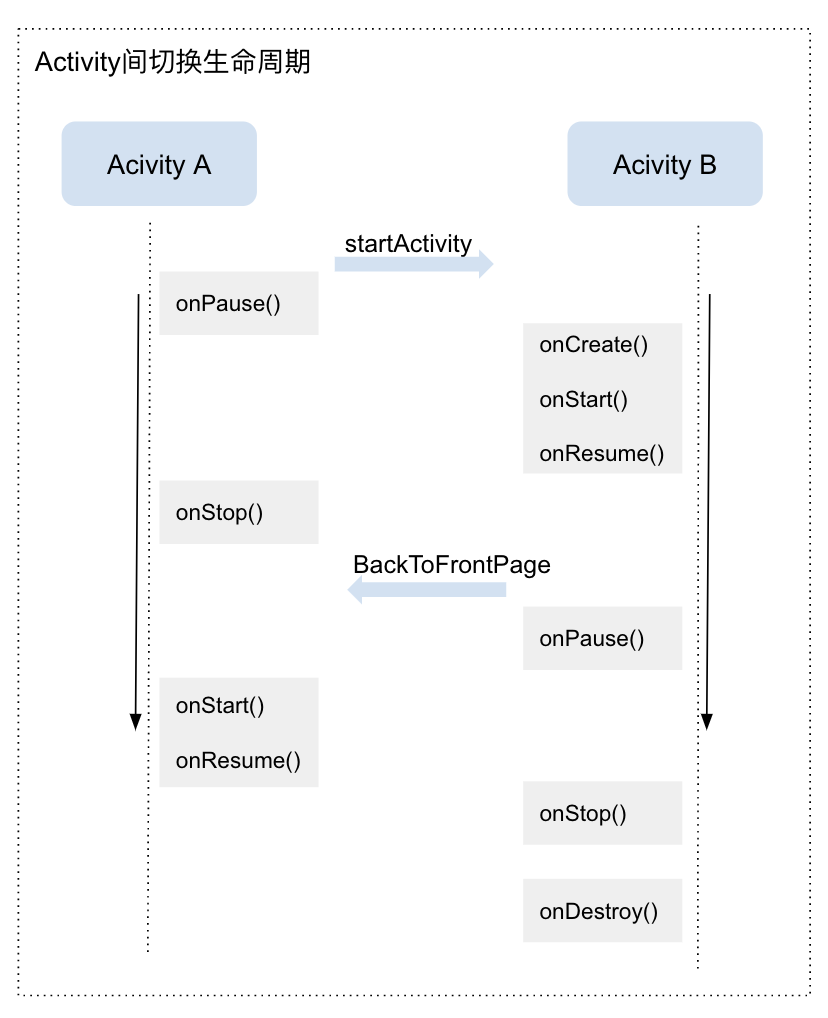 FlutterEngine 在原生层面定义了LifecycleChannel,主要作用是向 Flutter 发送渲染生命周期相关的事件。LifecycleChannel主要发送了四种状态事件:
FlutterEngine 在原生层面定义了LifecycleChannel,主要作用是向 Flutter 发送渲染生命周期相关的事件。LifecycleChannel主要发送了四种状态事件: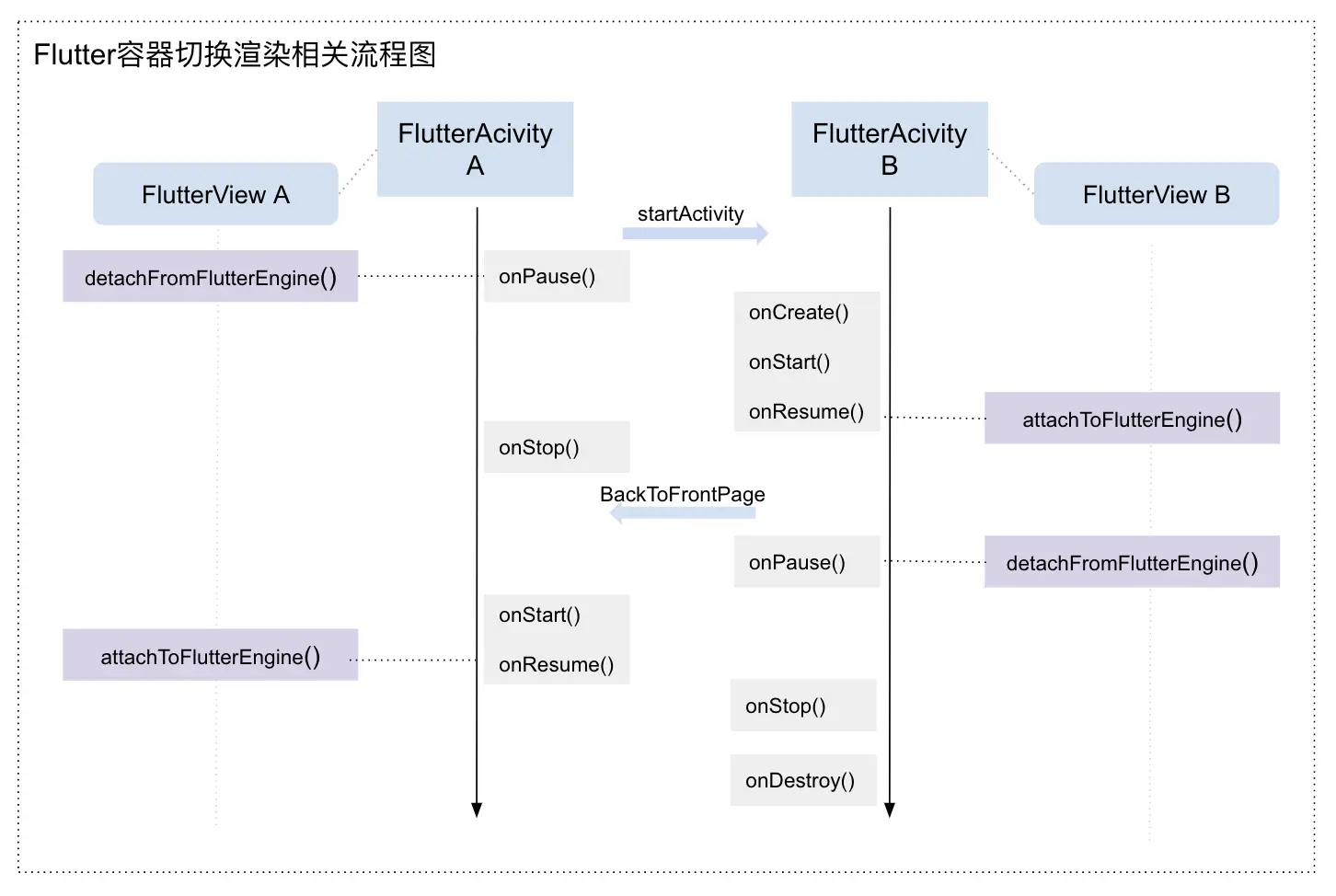
{kind=link}